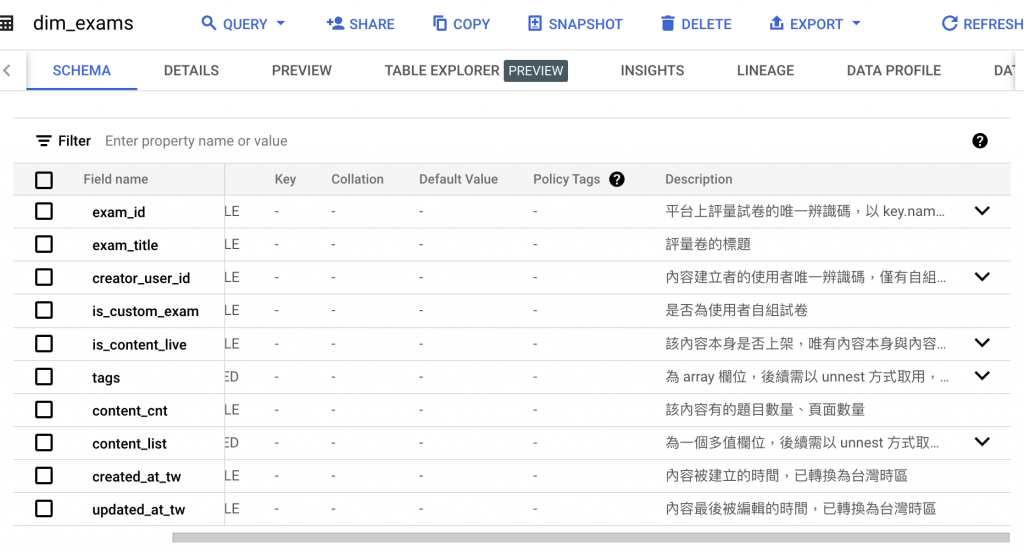
前面花了蠻多力氣講述欄位名稱要怎麼統一樣式,為的就是整齊、好辨認。
今天就來談談如何寫好文件!先從開發工具開始講起:
我們使用的是 dbt core,在 vscode 中開發模型,近來個人轉至 cursor,不過 extension 的部分是大同小異的。在其中,dbt power user 可說是萬能的好工具,今天就先來講它如何協助我們編輯文件。
當你完成模型的 sql code 之後,在模型下方,可以開啟一個 documentation editor 的視窗,只要你有建立過該表(dbt build),便可以同步於此,他會自動抓到所有欄位,把文件內容完成後,即可自動儲存成 yaml file,包含文件的架構,自動抓到每個欄位的名稱、型別,以及你寫入的說明。
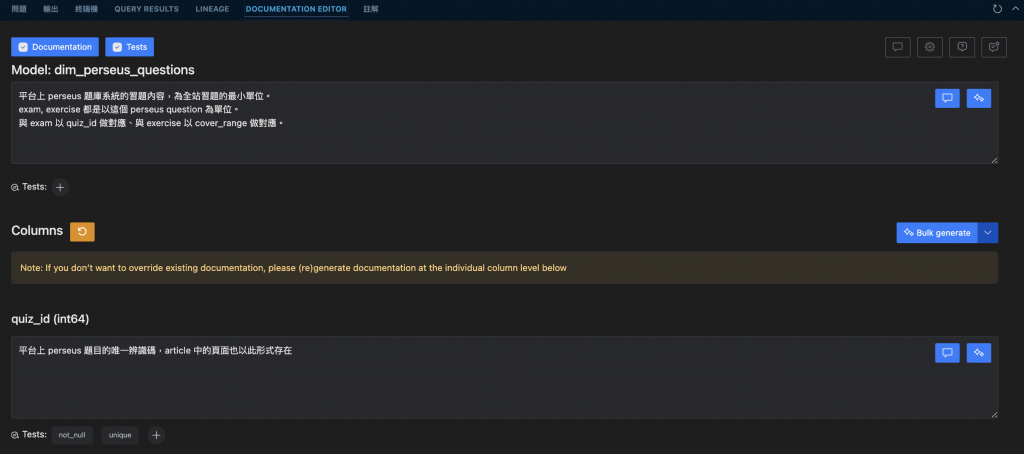
這個功能我們在導入的過程中,看他從無到有、逐漸齊全,真的是十分欣慰啊(欣慰什麼XD
一開始只能在裡面編寫文件,後來也可以在此編輯測試,not null, unique, accept_value 等等基礎測試,按一個按鈕就可以解決,若是自己有寫一些客製化測試,也可以在這邊加入。
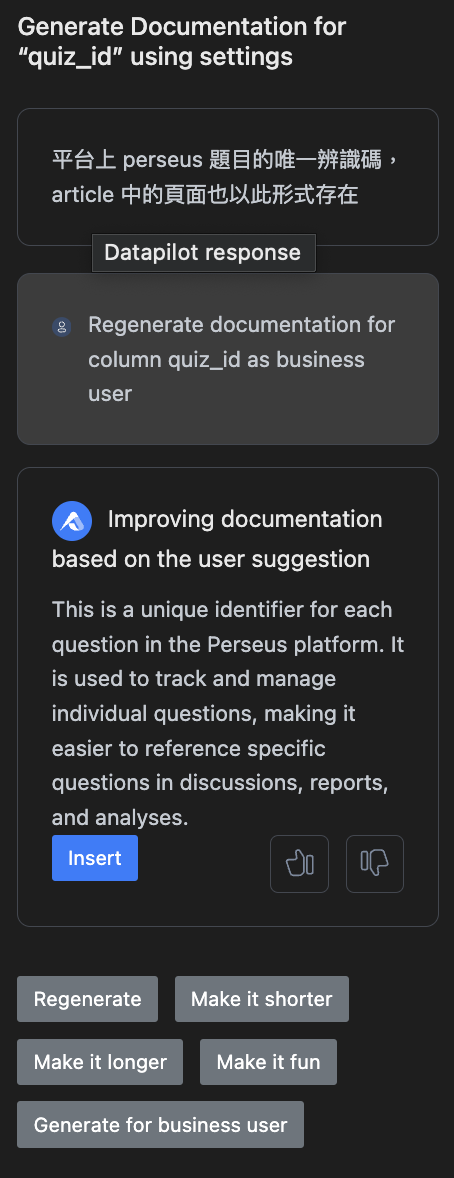
後來伴隨著 AI 浪潮,他也加入了 AI 工具,上方圖中右方的按鈕點擊幾下,便可以將通篇文件無中生有。
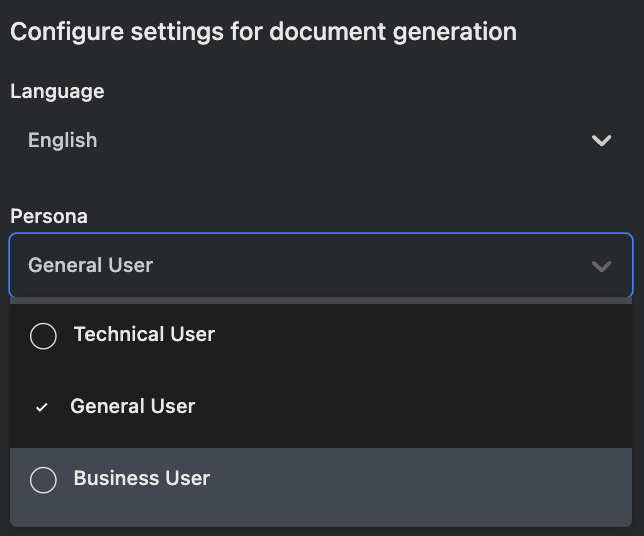
不僅如此,還可以做文件優化,如下圖,可以縮短、增長、make it fun(???),或是也可以設定這份文件的 TA 是普通人、技術人還是商業人,像是我在寫 staging, intermediate 的文件時,通常就會用比較多技術語言,而 marts 的文件就會比較白話,希望各個業務單位都能理解。
不過因為我們(我)覺得整篇英文文件看了實在有些疲憊,所以文件還是都以中文為主,目前該功能還未支援中文,沒什麼使用到 AI 生文件,好可惜 QQ
沒什麼用到的原因之一是語言,但其實完全可以用其他 AI 工具直接把整篇翻譯成中文。
最主要沒有使用的原因還是,寫文件終究是一門苦工,平台的 bug 會修復,資料卻是一直留存,有很多脈絡都伴隨著工程師一路走來修過的 bug,需要將這些脈絡都紀錄在欄位說明中。
譬如像是說明為什麼資料可能有什麼地方跟原先想像不同,可能是計算使用時間的方式有改變或優化、某個功能在某個時間點才開發出來,因此在這個時間點前沒有相關紀錄等等,比較難靠 AI 一鍵生成。
另外提一個 dbt 有趣的設定,叫做 persist_docs(文件)。
只要加上了這個設定,每次建立資料表時,就會自動將 yaml 文件的資訊同步於 BigQuery 的欄位說明中,輕易實現 single source of truth 的文件管理,不再像以前把文件寫在 notion,程式碼都更新不知道幾代了,文件還停留在遠古時期。